Reference
[Fluent Bit 3.0 Docs] Fluent Bit v3.0 Documentation
[Fluent Bit 3.0 Docs] Fluentd & Fluent Bit
[aws docs] Fluent Bit를 DaemonSet로 설정하여 CloudWatch Logs에 로그 전송
[Github] fluent / fluent-bit
[Better Stack] How to Collect, Process, and Ship Log Data with Fluent Bit
[tistory] Fluent Bit (With Loki)
[tistory] [EFK] EFK란(fluent bit 사용법)
[aws Blog] Fluent Bit Integration in CloudWatch Container Insights for EKS
[aws Blog] Centralized Container Logging with Fluent Bit
[aws Blog] Fluent Bit for Amazon EKS on AWS Fargate is here
[Fluent Bit 3.0 Docs] Format and Schema
1. Fluent Bit 개요
Fluent Bit는 고성능 로그 프로세서 및 로그 전달자로, CNCF(Cloud Native Computing Foundation)에 의해 호스팅되는 오픈 소스 프로젝트이다. 경량화되어 있고, C로 작성되었으며, 로그 데이터를 수집하고, 처리하고, 파이프라인을 통해 다양한 대상으로 전달하는 데 사용된다. Fluent Bit는 컨테이너화된 환경, 클라우드, 온-프레미스 시스템에서 로그 관리를 위해 널리 사용된다.

주요 특징
- 경량화 및 고성능: 컨테이너 및 마이크로서비스 아키텍처에 적합하도록 설계되었다.
- 다양한 입력 플러그인: 로그 파일, 시스템 메트릭, HTTP, MQTT 등 다양한 소스로부터 데이터를 수집할 수 있는 풍부한 입력 플러그인을 제공한다.
- 유연한 처리 파이프라인: 필터를 통해 데이터를 수정하거나 향상시킬 수 있으며, 조건부 로직을 적용하여 데이터를 처리할 수 있다.
- 다양한 출력 대상 지원: Elasticsearch, Kafka, HTTP, Fluentd 등 다양한 대상으로 데이터를 전송할 수 있는 출력 플러그인을 제공한다.
- 스트림 처리: 메모리 또는 파일 기반 버퍼를 사용하여 데이터 스트림을 효율적으로 처리한다.
사용 사례
- 로그 집계: 여러 출처에서 로그를 수집하여 중앙 집중식 로그 시스템으로 전송한다.
- 모니터링: 시스템과 애플리케이션에서 메트릭을 수집하여 모니터링 솔루션에 전송한다.
- 데이터 변환 및 정제: 로그 데이터를 필터링하고, 변환하여 저장소 또는 분석 도구에 전달하기 전에 데이터를 최적화한다.
구성 요소
- 입력 플러그인: 데이터 소스로부터 데이터를 수집한다.
- 파서: 수집된 로그 데이터의 형식을 해석한다.
- 필터: 데이터를 처리하고 변환한다.
- 출력 플러그인: 처리된 데이터를 다양한 대상으로 전송한다.
2. Fluent Bit vs Fluentd
- Fluent Bit
- 더 경량화되어 있고, 고성능을 위해 설계
- 2015년에 Treasure Data에서 만든 오픈소스 로그 수집기
- C로 작성 > 제한된 capacity, cpu, memory 환경을 고려
- 고도로 분산된 환경을 염두에 두고 만들어짐
- 추상화된 I/O 처리기는 비동기 및 event-driven read/write 작업을 지원

- Fluentd
- 많은 플러그인과 유연성을 제공
- 2011년에 만든 오픈소스 로그 수집기
- Ruby로 작성
- 리소스 사용량이 더 높음
- 1000개 이상의 다양한 플러그인 생태개 보유
- 4번째로 많이 사용되는 Docker 이미지
- Kubernetes 로깅하는데 주로 사용
$ git clone https://github.com/fluent/fluentd-kubernetes-daemonset
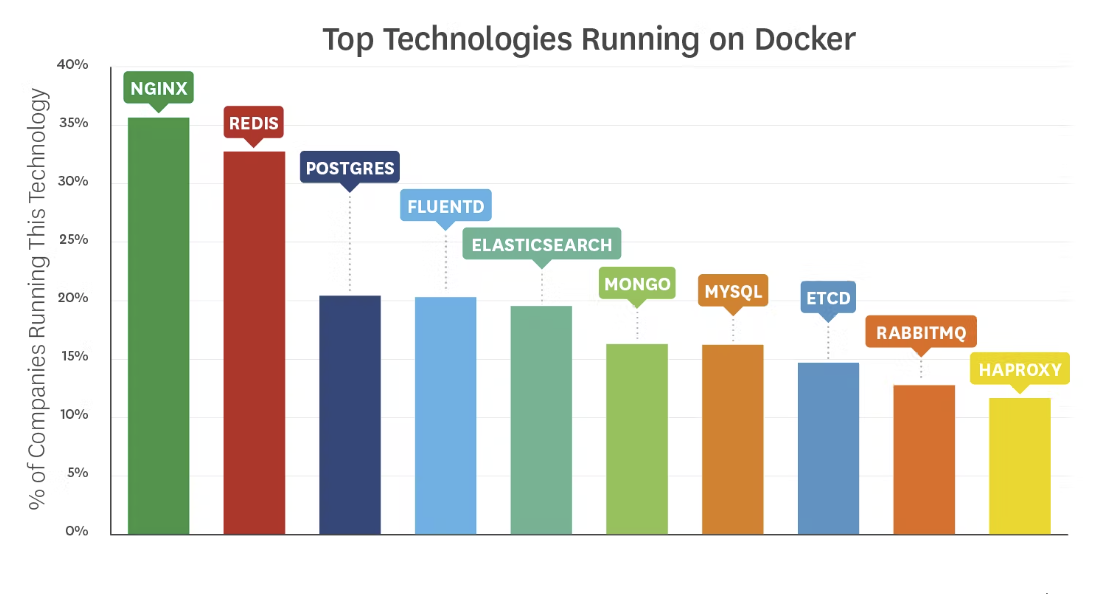
| Fluent Bit | Fluentd | |
| 개발 회사 | Treasure Data | Treasure Data |
| 로깅 방식 | 중앙 집중식 | 중앙 집중식 |
| Github | [Github] fluent / fluent-bit | [Github] fluent /fluentd |
| CNCF | O | O |
| Last Release Version | v3.0.0 | v1.16.5 |
| Last Release Update date | last week | 3 days ago |
| Release Source code Bytes | 26.9MB | 888KB |
| Scope | Embedded Linux / Containers / Servers | Containers / Server |
| Language | C | C & Ruby |
| Memory | ~1MB | > 60MB |
| Performance | High Perfermance | Medium Performance |
| Dependencies | Zero dependencies, unless some special plugin requires them. | Built as a Ruby Gem, it requires a certain number of gems. |
| Plugins | More than 100 built-in plugins are available | More than 1000 external plugins are available |
| License | Apache License v2.0 | Apache License v2.0 |
[Fluent Bit 3.0 Docs] Fluentd & Fluent Bit
- Fluent-Bit의 Release Source code Bytes가 더 큰 이유
- 추측1. 모든 의존성 파일을 포함하고 있다
3. 아키텍쳐
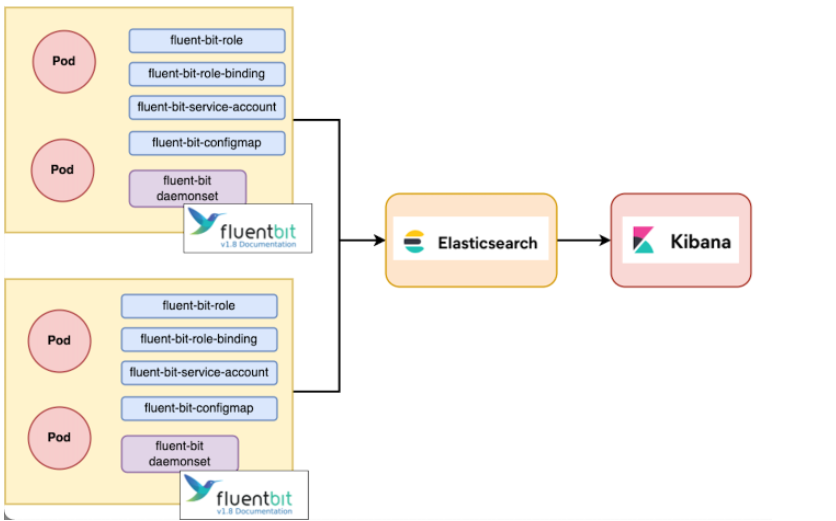
[tistory] [EFK] EFK란(fluent bit 사용법)
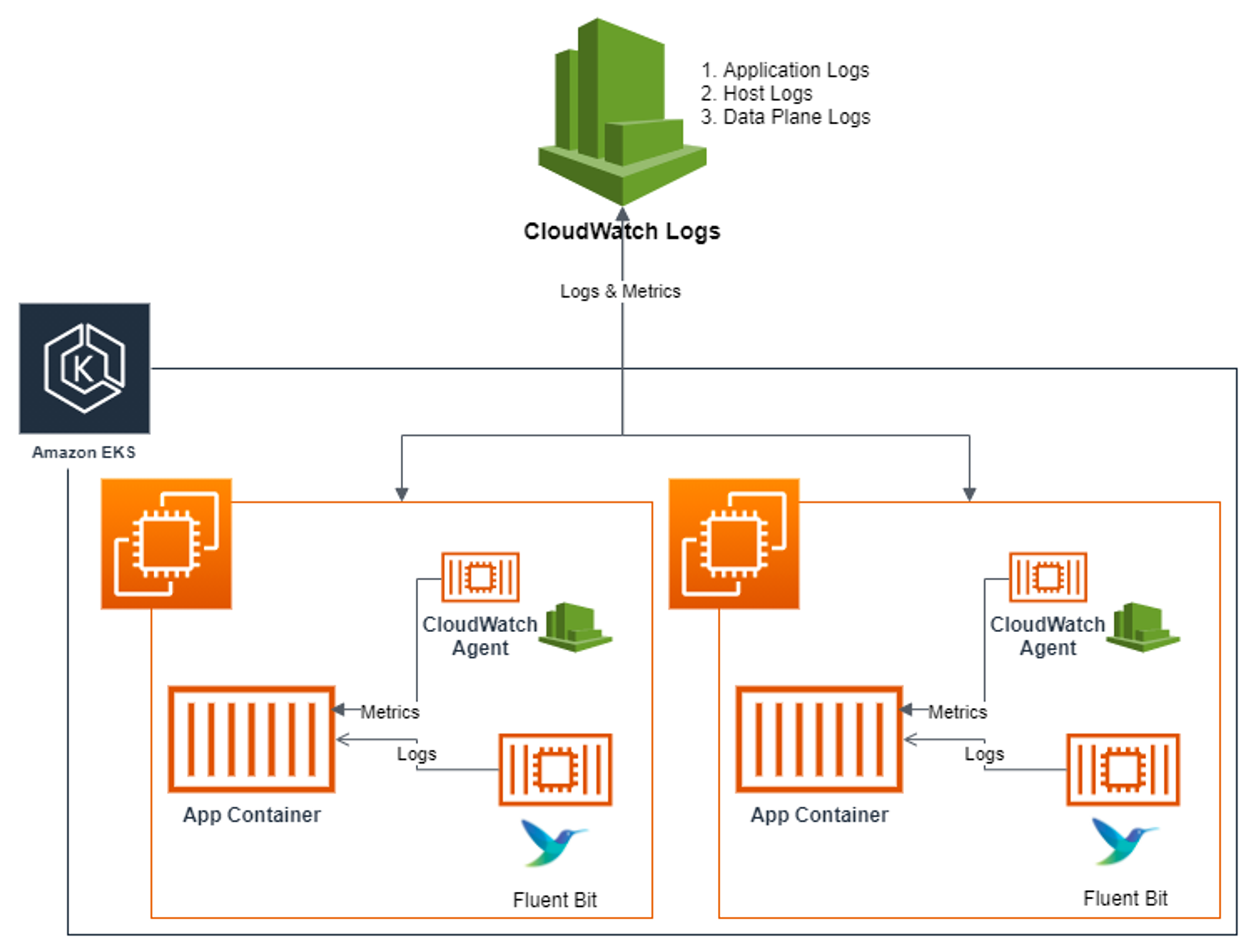
[aws Blog] Fluent Bit Integration in CloudWatch Container Insights for EKS
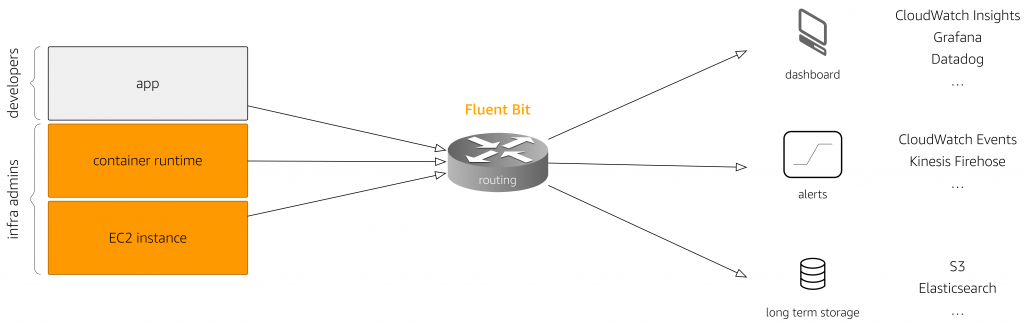
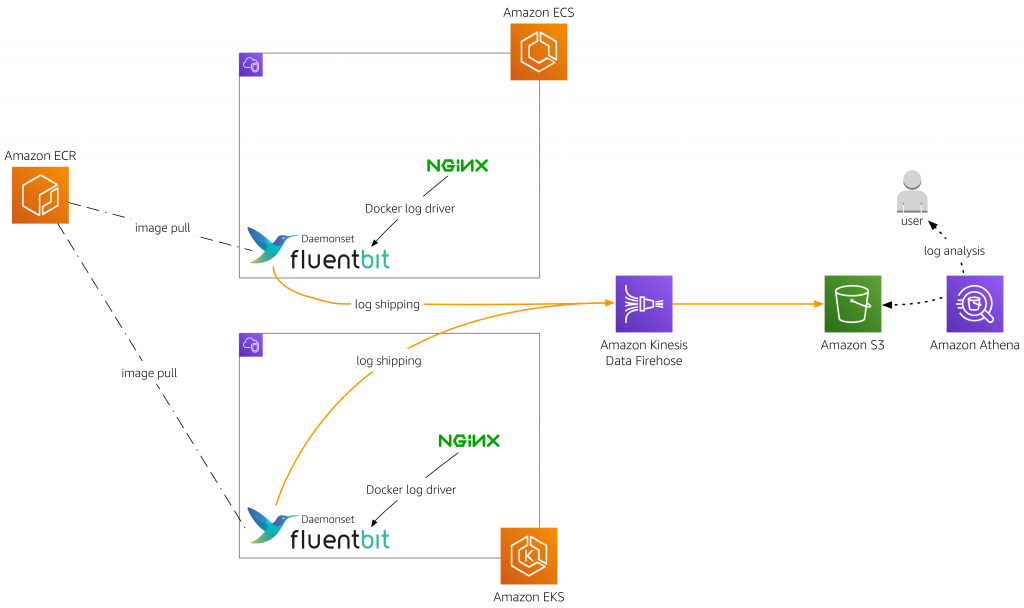
[aws Blog] Centralized Container Logging with Fluent Bit
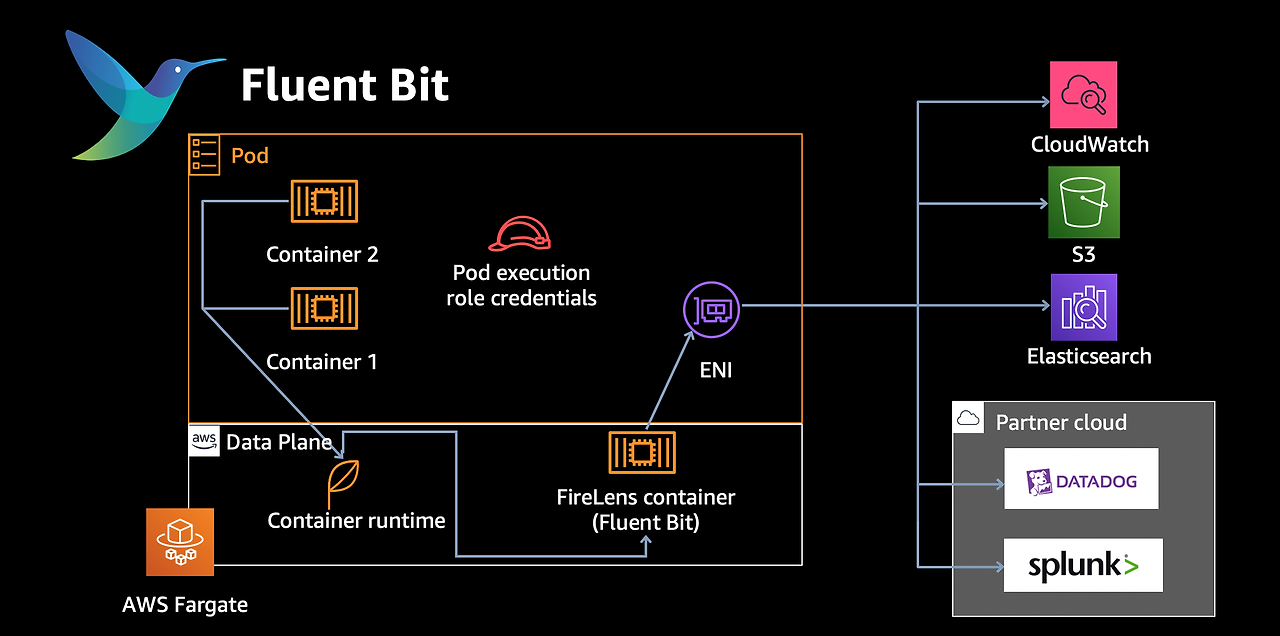
[aws Blog] Fluent Bit for Amazon EKS on AWS Fargate is here
4. Fluent Bit 형식 및 스키마
[Fluent Bit 3.0 Docs] Format and Schema
Fluent Bit은 구성 파일을 사용하여 서비스 작동 방식을 정의할 수 있다.
스키마는 세 가지 개념으로 정의된다.
- Sections
- Entries: Key/Value
- Indented Configuration Mode (4 spaces ideally)
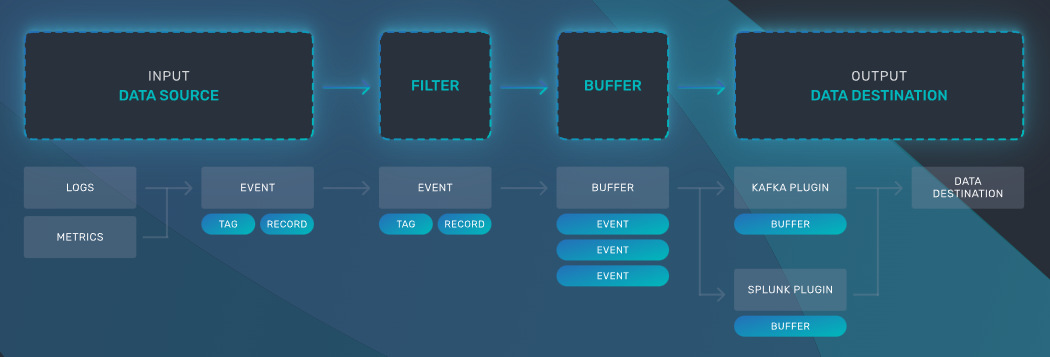
[fluentbit] Works for Logs, Metrics & Traces
Sections
섹션은 대괄호 안의 이름이나 제목으로 정의된다.
- 모든 섹션 내용은 들여쓰기되어야 한다(이상적으로는 4칸).
- 동일한 파일에 여러 섹션이 존재할 수 있다.
- 섹션에는 설명과 항목이 있어야 하며 비워둘 수 없다.
- 섹션 아래의 주석 처리된 줄도 들여쓰기해야 한다.
- 줄 끝 주석은 지원되지 않으며 전체 줄 주석만 지원된다.
주요 섹션에는 SERVICE, INPUT, FILTER, OUTPUT, 그리고 PARSER가 있다.
SERVICE
Fluent Bit의 전반적인 동작을 정의한다.
- Flush: 버퍼 데이터를 출력 플러그인으로 플러시하는 시간 간격(초)이다.
- Log_Level: 로그 출력 레벨을 설정한다(info, debug, error 등).
- info : 기본 로그 레벨로, 일반적인 작동 정보와 중요한 이벤트 메시지를 출력한다.
- debug : 더 상세한 로그를 출력하는 레벨로, 시스템의 작동 상태를 더 깊게 이해하기 위한 정보를 포함한다.
- error : 에러 메시지만을 출력한다.
- Parsers_File: 파서 정의를 포함하는 파일의 이름을 지정한다. 이 파일에는 로그 포맷을 해석하기 위한 정규 표현식이 정의된다.
[SERVICE]
Flush 1
Log_Level info
Parsers_File parsers.conf
INPUT
로그 데이터의 입력 소스를 정의한다.
- Name: 입력 플러그인의 이름을 지정한다(tail은 파일의 내용을 실시간으로 읽는다).
- Path: 로그 파일의 경로를 지정한다.
- Parser: 해당 로그 파일을 파싱하기 위해 사용할 PARSER 이름을 지정한다.
- Tag: 입력 데이터에 할당할 태그를 지정한다.
[INPUT]
Name tail
Path /var/log/nginx/access.log
Parser nginx_access_parser
Tag nginx_access
[INPUT]
Name tail
Path /var/log/nginx/error.log
Parser nginx_error_parser
Tag nginx_error
FILTER
입력 데이터를 처리하거나 변형하는 데 사용된다.
- Name: 필터 플러그인의 이름을 지정한다(grep, modify 등).
- grep : 정규 표현식 또는 특정 조건을 사용하여 로그 데이터를 필터링한다.
- Regex : 정규 표현식을 사용하여 로그 데이터 중 특정 패턴에 일치하는 데이터만을 선택한다.
- Exclude : 정규 표현식에 일치하는 데이터를 제외하고 처리한다.
- modify : 그 데이터에 필드를 추가, 삭제 또는 수정하는 작업을 수행한다.
- Add: 새로운 키-값 쌍을 로그 데이터에 추가한다.
- Remove: 지정한 키를 로그 데이터에서 삭제한다.
- Rename: 로그 데이터의 키 이름을 변경한다.
- grep : 정규 표현식 또는 특정 조건을 사용하여 로그 데이터를 필터링한다.
- Match: 이 필터가 적용될 태그 패턴을 지정한다.
- Regex: grep 필터를 사용할 경우, 로그 메시지를 필터링하기 위한 정규 표현식을 지정한다.
- Add: modify 필터를 사용할 경우, 로그 메시지에 추가할 필드를 지정한다.
[FILTER]
Name grep
Match nginx_access
Regex log .*somaz.*
[FILTER]
Name modify
Match nginx_access
Add log_type nginx_access
[FILTER]
Name modify
Match nginx_error
Add log_type nginx_error
OUTPUT
처리된 로그 데이터의 최종 목적지를 정의한다.
- Name: 출력 플러그인의 이름을 지정한다(stdout, loki 등).
- Match: 이 출력이 적용될 태그 패턴을 지정한다.
- Host, Port, URI: 로그 데이터를 전송할 대상 서버의 주소와 포트, URI를 지정한다.
- tls: TLS/SSL을 사용하여 데이터 전송을 암호화할지 여부를 지정한다.
- Labels: 로그 데이터와 함께 전송할 레이블을 지정한다.
[OUTPUT]
Name stdout
Match *
[OUTPUT]
Name loki
Match *
Host loki.somaz.link
Port 443
URI /loki/api/v1/push
tls On
Labels job=fluent-bit, log_type=$log_type
PARSER
로그 데이터의 포맷을 해석하는 규칙을 정의한다.
- Name: 파서의 이름을 지정한다.
- Format: 파싱할 로그 포맷의 유형을 지정한다(regex 등).
- Regex: 로그 메시지를 파싱하기 위한 정규 표현식을 지정한다.
- Time_Key, Time_Format: 로그 메시지에서 시간을 추출하기 위한 키와 시간 포맷을 지정한다.
[PARSER]
Name nginx_access_parser
Format regex
Regex ^(?<remote_addr>[^ ]*) - (?<remote_user>[^ ]*) \\[(?<time>[^\\]]*)\\] "(?<method>\\S+) (?<request>[^ ]*) (?<http_protocol>[^"]*)" (?<status>[^ ]*) (?<body_bytes_sent>[^ ]*) "(?<http_referer>[^"]*)" "(?<http_user_agent>[^"]*)" (?<request_length>[^ ]*) (?<request_time>[^ ]*) \\[(?<upstream_name>[^\\]]*)\\] \\[(?<upstream_addr>[^\\]]*)\\] (?<upstream_response_length>[^ ]*) (?<upstream_response_time>[^ ]*) (?<upstream_status>[^ ]*) (?<request_id>[^ ]*)$
Time_Key time
Time_Format %d/%b/%Y:%H:%M:%S %z
[PARSER]
Name nginx_error_parser
Format regex
Regex ^(?<time>\\d{4}/\\d{2}/\\d{2} \\d{2}:\\d{2}:\\d{2}) \\[(?<log_level>\\w+)\\] (?<process_info>\\d+#\\d+): (?<message>.*)$
Time_Key time
Time_Format %Y/%m/%d %H:%M:%S
nginx_access_parser
- Format: regex - 정규 표현식을 사용하여 로그의 구조를 분석한다.
- Regex: 이 정규 표현식은 Nginx 접근 로그의 일반적인 형식을 분석하기 위해 설계되었다. 각 그룹((?<name>...))은 로그의 특정 부분을 캡처하고, 해당 부분에 이름을 할당한다. 예를 들어, remote_addr, remote_user, time, method, request, http_protocol, status 등의 필드를 추출한다.
- Time_Key: time - 로그에서 시간 정보를 포함하는 필드의 이름이다.
- Time_Format: %d/%b/%Y:%H:%M:%S %z - 로그에 기록된 시간의 형식을 나타냅니다. 이 형식은 파싱 과정에서 시간 정보를 올바르게 해석하기 위해 사용된다.
nginx_error_parser
- Format: regex - 정규 표현식을 사용하여 에러 로그의 구조를 분석한다.
- Regex: Nginx 에러 로그의 특정 패턴을 분석하기 위한 정규 표현식이다. 여기서는 시간(time), 로그 레벨(log_level), 프로세스 정보(process_info), 그리고 실제 메시지(message) 등의 필드를 추출한다.
- Time_Key: time - 에러 로그에서 시간 정보를 담고 있는 필드의 이름이다.
- Time_Format: %Y/%m/%d %H:%M:%S - 에러 로그에 기록된 시간의 형식을 나타낸다.


